
Command Query Responsibility Segregation (CQRS) ist ein Architekturentwurfsmuster zur Trennung von lesenden und schreibenden Zugriffen. Der Begriff wurde 2010 von Greg Young geprägt und hat sich schnell etabliert.
CQRS is simply the creation of two objects where there was previously only one
Greg Young
CQRS ist eine Fortführung von CQS, auf das ich im nächsten Abschnitt näher eingehe. Der reinen Definition nach handelt es sich bei CQRS um ein einfaches Entwurfsmuster, jedoch wird der Einsatz von CQRS oftmals von bedeutsamen Architekturentscheidungen begleitet, die ich in diesem Beitrag ebenfalls näher beleuchten möchte, daher die Einordnung in der Rubrik „Architektur“.
CQS
Command Query Separation (CQS) ist ein Prinzip der objektorientierten Programmierung von Bertrand Meyer, das er während der Entwicklung der Sprache Eiffel formuliert und auch in seinem 1988 erschienen Buch Object Oriented Software Construction beschrieben hat.
Asking a question should not change the answer
Bertrand Meyer
Das Prinzip ist auf Methodenebene angesiedelt, wobei Methode hier auch stellvertretend für Funktion, Prozedur und Subroutine steht.
Eine Methode, die etwas zurückgibt und dabei den Zustand eines Objektes nicht verändert, nennt man Query. Eine Methode, die den Zustand eines Objektes verändert, aber keinen Rückgabewert hat, nennt man Command. Eine Methode darf nicht gleichzeitig etwas zurückgeben und den Zustand verändern, sie muss entweder als Query oder als Command vorliegen.
Das Prinzip erinnert an die Unterteilung von Subroutinen in Funktionen und Prozeduren in der Sprache Pascal. Nach Niklaus Wirth enthält eine Programmbibliothek – oder Unit, Pascal hatte ursprünglich keine Unterstützung für Objektorientierung – Actions und Values. Prozeduren zählen dabei zu den Actions, Funktionen zu den Values. Die Intention einer Prozedur, eine Aktion auszulösen, entspricht dem Command in CQS. Die Intention einer Funktion, einen Wert zurückzugeben, entspricht dem Query in CQS.
Ein populäres Beispiel einer Methode, die sich nicht an CQS hält, ist pop() in einem Stack oder einer Queue. Diese Methode, manchmal auch unter anderem Namen, gibt es in diversen Sprachen. Sie entfernt gleichzeitig ein Element von einem Stack bzw. aus einer Queue und gibt dieses dann zurück. Ein weiteres Beispiel ist die Methode next() eines Iterators, die es z.B. in Java und Python gibt, und die das nächste Element einer Iteration zurückgibt. Beim Aufruf von next() bewegt sich der Zeiger zum nächsten Element in der Iteration. Beide Beispiele haben gemeinsam, dass sie nicht idempotent sind und den Zustand eines Objektes mit jedem Aufruf weiter verändern. Queries nach CQS hingegen sind idempotent. Der Rückgabewert ändert sich erst, wenn sich der Zustand durch ein zwischenzeitlich ausgeführtes Command geändert hat.
CQRS
Greg Young überträgt CQS auf Klassen. Eine Command-Repräsentation einer Entität wird verwendet, um den Zustand der Entität zu verändern. Eine Query-Repräsentation einer Entität wird verwendet, um den Zustand abzufragen. Auch wenn Greg Young als Erfinder des Begriffes die Deutungshoheit hat, so wird CQRS von vielen als Übertragung von CQS von der Methoden- auf die Anwendungsebene aufgefasst. Die Anwendung von CQRS bedeutet damit nicht ausschließlich, dass es für jedes relevante Modell eine Query- und eine Command-Abbildung gibt, sondern kann auch implizieren, dass die komplette API in eine Query- und eine Command-API aufgeteilt ist, bis dazu hin, dass Query- und Command-Anteil in verschiedenen Services beheimatet sind und damit unabhängig voneinander skaliert werden können, ggf. sogar verschiedene Datenspeicher verwenden.
Abgrenzung CQRS, DDD und ES
CQRS wird gerne in Kombination mit Domain-driven Design (DDD) und Event Sourcing (ES) verwendet. Alle drei Ansätze sind jedoch unabhängig voneinander, können also ohne die anderen auskommen. Zusätzlich sei erwähnt, dass CQRS sehr gut in einer ereignisgesteuerten Architektur funktioniert, jedoch weder eine solche erfordert noch Commands asynchron verarbeitet werden müssen.
CQRS mit getrennten Services
Wird CQRS in einem verteilten System mit hohen Anforderungen an die Skalierung eingesetzt, kann man den Query-Anteil und den Command-Anteil in unterschiedlichen Services unterbringen. Oftmals herrscht kein Gleichgewicht zwischen lesenden und schreibenden Zugriffen, so dass eine individuelle Skalierung die Performance verbessern kann. Bei einer Wikisoftware ist es plausibel, dass die Mehrheit der Zugriffe lesender Natur ist. Schließlich ist ein Wiki in erster Linie ein Nachschlagwerk. Eine hohe Anzahl an Query-Service-Instanzen kann dazu beitragen, dass Leseanfragen sehr schnell beantwortet werden können, unabhängig davon, wie viele Schreibanfragen gerade in Ausführung sind.
CQRS mit getrennten Datenspeichern
Eine vollständige Entkopplung lässt sich erreichen, indem auch die Datenbanken für Commands und Queries getrennt werden. Diese Trennung führt jedoch dazu, dass man sich mit Eventual Consistency auseinandersetzen und die Datenbanken synchronisieren muss. In einer klassischen relationalen Datenbank mit ACID (atomicity, consistency, isolation, durability) hat man keine wirkliche Entkopplung von Command und Query. In Ausführung befindliche Transaktionen können den Lesezugriff immer noch ausbremsen. Eine Entkopplung der Datenbanken ermöglicht ein unabhängiges Tuning der Leseanfragen. Um eine möglichst hohe Geschwindigkeit zu erreichen, kann man komplett auf Normalisierung und damit auf Joins in den Selektionen verzichten und die Daten flach ablegen. Eine flache Struktur impliziert mehr Redundanzen und damit zusätzlichen Speicherbedarf, spätestens bei M-zu-N-Beziehungen. Das genaue Design ist letzlich eine individuelle Abwägung je nachdem, welche Stellenwerte Geschwindigkeit, Speicherbedarf und weitere nicht funktionale Aspekte haben.
CQRS auf Architekturebene – ein Beispiel
In meinem aktuellen Arbeitsumfeld setzen wir CQRS auf Architekturebene für eine Suchmaschine ein. Die Command-Seite hat eine ereignisgesteuerte Architektur. Aus verschiedenen Quellen werden Ereignisse empfangen, die verarbeitet und konsolidiert in einer Command-seitigen Datenbank abgelegt werden. Der Suchindex entspricht der Query-Datenbank und wird regelmäßig automatisch aktualisiert. Die Daten im Suchindex sind auf Geschwindigkeit optimiert in einer flachen Struktur abgelegt. Bei der nächsten Synchronisierung wird die Query Database komplett weggeräumt und von Grund auf neu erstellt.
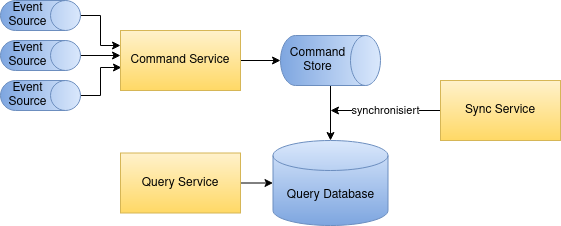
Eventual Consistency spielt eine Rolle in dieser Architektur, denn zum Zeitpunkt der Synchronisierung kann es sein, dass eine Änderung, die sich in mehreren Ereignissen widerspiegelt, noch nicht vollständig verarbeitet ist. Für den konkreten Anwendungsfall der Suche spielt dies allerdings nur eine untergeordnete Rolle, da die Suche selbst nur Identifikationsnummern und keine Stammdaten zurückliefert und sich Inkonsistenzen wenn überhaupt nur minimal auf die Suchqualität auswirken.
Referenzen auf neue Datensätze
Ein interessanter Gedanke ist, wie man neu eingefügte Datensätze referenzieren kann. Ein Beispiel: In einem CRM möchte ich einen neuen Kundendatensatz anlegen. Kunden erhalten dabei eine einzigartige, fortlaufende Kundennummer. Das Command könnte so aussehen:
// kein Getter/Setter/Konstruktor, nur ein Beispiel
class CreateCustomerCommand {
String name;
}
Angenommen ich möchte zu dem Kunden im Anschluss eine Adresse pflegen. Wie weiß ich, dass das Command erfolgreich verarbeitet wurde und wie kann ich den Kunden nach Anlage eindeutig identifizieren? Ich möchte dazu mehrere Ansätze mitgeben:
- Jedes Command erzeugt ein Ereignis. Das Ereignis beinhaltet neben dem Namen auch die vergebene Kundennummer. Eine nicht erfolgreiche Anlage führt zu einem Fehlerereignis oder es wird eine Exception geworfen.
- Der Command-Service, der das Command entgegennimmt, liefert als Rückgabewert die Kundennummer. Zwar stellt dies auf den ersten Blick eine Verletzung dar, andererseits dient CQRS der Anwendung und nicht andersrum. Eine einfache saubere Lösung ist einem dogmatischen Befolgen des Ansatzes bei Inkaufnahme diverser Nachteile zu bevorzugen.
- Die nächste freie Kundennummer wird im Voraus über eine entsprechende Query ermittelt und direkt im Command mitgegeben. In einem parallelen System müssen dabei die üblichen Herausforderungen wie Race Conditions berücksichtigt werden.
- Das Command wird über eine UUID (Universally Unique Identifier), auch als GUID (Globally Unique Identifier) bekannt, referenziert. Dabei generiert der Client selbst eine ID, die aufgrund ihrer Länge mit einer extrem hohen Wahrscheinlichkeit eindeutig ist. Die UUID wird im Command mitgegeben und ermöglicht es später, das Command bzw. das erzeugte oder aktualisierte Objekt eindeutig zu referenzieren.
Wann man CQRS einsetzen sollte
Der größte Mehrwert von CQRS ist das Potenzial bei der Skalierung. Im geschilderten Beispiel aus meinem Arbeitsumfeld stand der Begriff CQRS gar nicht im Raum, die Architektur ist alleinig durch die Anforderungen an die Suche entstanden.
CQRS im Allgemeinen unterscheidet sich deutlich von CRUD (create, read, update, delete) und sollte nur dann eingesetzt werden, wenn die Entwickler sich auf dieses Paradigma einlassen können und wollen. CQRS erfordert mehr Überlegungen beim Design, bedeutet aber auch eine inhärente Separation of Concerns, erleichtert das Befolgen gängiger Prinzipien wie dem Single Responsibility Principle und kann allgemein Clean Code und der Testbarkeit von Code sehr zuträglich sein. Auch für die Sicherheit kann die logische Trennung von Commands und Queries dienlich sein, wobei in allen Fällen CQRS allein nicht die Lösung ist, sondern sich vielmehr die saubere und konsequente Umsetzung auszahlt.
CQRS bedeutet in jedem Fall Mehraufwände und eine höhere Komplexität, und sollte daher überhaupt erst ab einer gewissen Größe infrage kommen. CQS hingegen ist kaum mit weiteren Kosten verbunden, aber auch nur dann sinnvoll, wenn sich konsequent daran gehalten wird. Dann wiederum gibt es Fälle, wo eine Abkürzung sinnvoll ist und ein starres Befolgen von CQS mehr schadet als nützt, siehe die Beispiele pop() und next() weiter oben im Beitrag.
- Abgrenzung von Greg Young - Beschreibung von Martin Fowler