
Event Sourcing ist ein Architekturmuster, bei dem sich der State einer Anwendung aus einer Folge von Events ergibt. Der Begriff Event Sourcing wurde von Martin Fowler geprägt und kann so verstanden werden, dass der Zustand in eine Menge von Events als die Quelle aller Wahrheiten ausgelagert wird.
Funktionsweise und Beispiele
Im Event Sourcing werden alle Änderungen am Zustand eines Systems als Ereignisse in eindeutiger chronologischer Folge in einem Event Log abgelegt. Aus der Verarbeitung dieser Ereignisse in der gegebenen Reihenfolge ergibt sich der aktuelle Zustand des Systems.
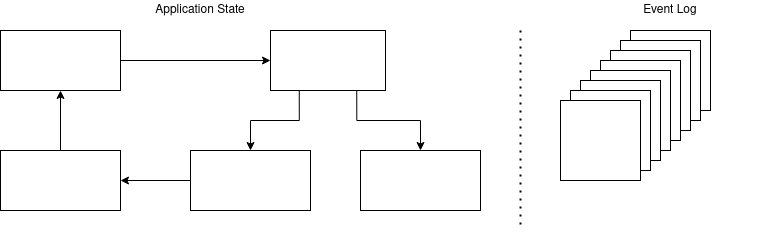
Der Ansatz des Event Sourcings steht im Gegensatz zu einer klassischen CRUD-Applikation. CRUD steht für Create, Read, Update und Delete. Je nach Aktion werden Daten entweder angelegt, gelesen, aktualisiert oder gelöscht. In der Datenbank einer CRUD-Applikation manifestiert sich damit immer der aktuelle Application State. Historische Informationen hingegen bleiben nicht erhalten, sofern dies im Design der Anwendung nicht explizit vorgesehen wird. Im Event Sourcing ist der Application State ephemerischer Natur. Beim Start der Anwendung wird der State nicht aus einem Speicher gelesen, sondern er wird rekonstruiert, indem alle Events im Event Log erneut abgespielt werden.
Event Sourcing verzichtet auf das „UD“ von CRUD, es verbleibt das „CR“. Einmal angelegt sind Events unveränderlich und können nicht gelöscht werden. Um eine Änderung aufzuheben wird ein neues Event angelegt, das dieses negiert.
Versionskontrollsysteme sind populäre Beispiele für den Einsatz von Event Sourcing. In Systemen wie Git und Subversion lässt sich jeder historische Zustand auf Knopfdruck wiederherstellen. Möchte man in Git einen Commit reverten, so wird dieser nicht aus der Historie entfernt, sondern es findet eine Gegenbuchung statt. Kontostände ergeben sich aus einer Folge von Einzahlungen und Abbuchungen und sind ebenfalls für den Einsatz von Event Sourcing prädestiniert. Warenwirtschaften sind ein weiteres gutes Beispiel: Lagerbestände von Artikeln sind das Resultat von Einkäufen und Verkäufen bzw. Bewegungen des Artikels. Belege für Aufträge, Lieferscheine und Rechnungen erfordern für nachträgliche Änderungen in der Regel einen neuen Korrekturbeleg anstatt dass der ursprüngliche Beleg angepasst wird.
Vollständige Transparenz
Event Sourcing impliziert, dass jede Änderung im System transparent und nachvollziehbar bleibt. Damit werden gleich drei Aspekte erschlagen, für die normalerweise separat Daten gesammelt werden:
- Auditing
- Logging
- Reporting
Durch Event Sourcing ergibt sich automatisch ein Audit-Log, da sämtliche Kontextinformationen aller jemals durchgeführten Änderungen historisiert werden. Die Vollständigkeit der vorliegenden Informationen macht ein zusätzliches Logging redundant, denn warum sollte man Kontextinformationen loggen, die bereits im Event Log vorliegen? Nun, es gibt vielleicht eine Ausnahme. Ein Event sollte nur absolute Werte enthalten. Bei einer Kontoabbuchung sind dies unter anderem die Kontonummer, der Empfänger, der Betrag und der Zeitpunkt. Der Kontostand vor oder nach der Transaktion sollte aber nicht Teil der Event-Informationen sein, da es sich um einen abgeleiteten Wert handelt, der sich aus den vorherigen Events ergibt. Ich würde aber behaupten, dass solche Informationen in der Regel nicht zusätzlich geloggt werden müssen, da das Event Log jederzeit neu abgespielt werden kann. Das Event Log ist auch eine gute Grundlage für ein Reporting. Events können für eine bestimmte Zeitspanne betrachtet und aggregiert werden, um etwa zu berechnen, wie viele Transaktionen es an einem Tag gegeben hat, oder wie hoch der durchschnittliche Betrag einer Transaktion in einem gegebenen Zeitraum war.
Reproduzierbarkeit von Zuständen
Event Sourcing kann nicht nur den aktuellen Application State wiederherstellen, sondern auch Zustände aus der Vergangenheit. Dies kann eine Business-Anforderung sein, es kann aber auch die Entwicklung beim Debugging und der Fehleranalyse sehr gut unterstützen. Entwickler können das Event Log eines Produktivsystems in ein Entwicklungssystem übertragen, und dort beobachten, wie sich Fehlerkorrekturen und Änderungen auf den Zustand des Systems auswirken. Sollte sich ein Verhalten tatsächlich nicht unmittelbar aus den vorliegenden Events erschließen, kann der Code durch ein Debug-Logging angereichert und das Event Log erneut durchlaufen werden.
Event Sourcing ermöglicht dabei ein sehr schnelles Feedback, da idealerweise nur ein Mausklick erforderlich ist, um nach einer Anpassung den neuen Stand zu berechnen und zu vergleichen. Integrationstests können mit Event Sourcing einfach und einheitlich umgesetzt werden, indem für den Testfall der Zustand des Systems nach Abarbeitung eines definierten Event Logs gemessen wird.
Performance
Ein Geschwindigkeitsvorteil von Event Sourcing gegenüber herkömmlichen CRUD-Anwendungen kann dadurch erzielt werden, dass der gesamte Application State im Arbeitsspeicher abgelegt wird, während eine typische Datenbank die Festplatte als Datenspeicher verwendet und oftmals über das Netzwerk angesprochen wird.
Snapshots
Mit der Zeit steigt die Anzahl der Einträge im Event Log und damit unweigerlich die Zeit, die benötigt wird, all diese Events abzuarbeiten. Dementsprechend kommt man in den meisten Fällen kaum darum herum, regelmäßige Snapshots zu machen. Ein Snapshot selbst kann durch eine Menge von Events repräsentiert werden, als Binärdatei vorliegen oder in einem Datenspeicher abgelegt sein. Bei Wiederherstellung des Systems müssen dann nur der Snapshot selbst und die zwischenzeitlich neu hinzugekommenen Events verarbeitet werden, um den aktuellen Zustand zu berechnen.
Mit der wachsenden Zahl an Events steigt nicht nur die Dauer der Verarbeitung, auch der Speicherbedarf wächst weiter. Verwirft man alle Events vor einem Snapshot, so verliert man aber auch die Auditing-/Logging- und Reporting-Vorteile von Event Sourcing. Eine pauschale Empfehlung zum Vorgehen ist nicht möglich und hängt von vielen Fragestellungen ab:
- Wie weit in die Vergangenheit werden Daten fürs Auditing/Logging/Reporting benötigt?
- Wie weit in die Vergangenheit soll der Zustand des Systems reproduzierbar bleiben?
- Wie viele Events fallen in welcher Zeitspanne an?
- Wie lange dauert die durchschnittliche Verarbeitung eines Events?
- Wie viel Platz benötigt ein Event im Durchschnitt?
Die Verwendung von Snapshots ist unabhängig vom Löschen alter Events. Ein System kann also auch wöchentlich einen Snapshot machen und die Events der letzten sechs Monate vorhalten. Soll ein historischer Zustand rekonstruiert werden, so wird der zu diesem Zeitpunkt jüngste Snapshot verwendet und alle darauffolgenden Events bis zu diesem Zeitpunkt verarbeitet. Eine solche Strategie kann sich anbieten, wenn die benötigte Rechenleistung zur Verarbeitung aller Events ein größeres Problem darstellt als der benötigte Speicherplatz.
Getrennte Modelle zum Lesen und Schreiben
Event Sourcing ist prädestiniert dafür, getrennte Modelle zum Lesen und Schreiben zu verwenden. Dieses Vorgehen ist unter dem Begriff CQRS (Command Query Responsibility Segregation) bekannt. Das Event Log ist ein ideales Write Model, da immer nur Einträge am Ende der Queue hinzugefügt werden. Der Application State ist die Grundlage für das, was im System dargestellt wird und welche Operationen möglich sind, also das Read Model. Das Read Model muss permanent mit dem Write Model synchronisiert werden, indem neue Events im Event Log verarbeitet werden und das Read Model aktualisieren. Dies kann synchron oder asynchron realisiert werden. Letzteres kann zu einer besseren Performance führen, man muss sich dann aber mit Eventual Consistency auseinandersetzen. Ein Beispiel: Die Registrierung an einem System erfordert einen eindeutigen Benutzernamen. Existieren Events im Event Log, die noch nicht in das Read Model eingegangen sind, so kann nicht garantiert werden, dass ein gewählter Benutzername nicht doch schon vergeben ist.
Event Sourcing kann ohne CQRS realisiert werden. In dem Fall würden bei jeder Query alle Events (seit dem letzten Snapshot) verarbeitet werden.
Weiterentwicklung des Codes
Eine Anwendung auf Basis von Event Sourcing weiterzuentwickeln, gestaltet sich ähnlich schwierig wie Änderungen an einer Schnittstelle vorzunehmen. Eine Änderung kann unterschiedlichster Natur sein:
- Ein Event wird um zusätzliche Felder erweitert
- Bestehende Felder eines Events werden durch andere ersetzt, z.B. zusammengelegt oder getrennt: statt „Name“ soll es zukünftig die Felder „Vorname“ und „Nachname“ geben
- Ein Fehler in der Verarbeitung eines Events wird korrigiert
- Die Verarbeitung eines Events wird aus fachlichen Gründen geändert
- Die Verarbeitung eines Events wird aus technischen Gründen geändert
Der Umgang mit diesen Herausforderungen ist hochindividuell. Eine Lösung für Änderungen an einem Event ist es, diese zu versionieren. Statt eines Event KundeAngelegt gibt es ein Event KundeAngelegtV1. Ändert sich die Struktur des Events, wird dies in einem neuen Event KundeAngelegtV2 abgebildet. Im Event Log bereits existierende Events vom Typ KundeAngelegtV1 werden dabei nicht geändert. Soll eine Datenmigration stattfinden, z.B. der oben beschriebene Fall, dass „Name“ in „Vorname“ und „Nachname“ aufgetrennt wird, so wird dies über ein neues Event KundeNameMigriertV1 realisiert. Da die Daten des Events eng an die Verarbeitung des Events gekoppelt sind, sollte die Verarbeitungslogik möglichst dicht am Event sein. Es bietet sich also an die Verarbeitung ebenfalls zu versionieren, oder sogar zum Teil des Events zu machen.
Externe Schnittstellen
Wird über ein Event eine Bestellung in einem externen System ausgelöst, so darf dies nicht bei wiederholter Rekonstruktion des Application States geschehen. Ich würde daher sowohl die an das externe System gesendeten Informationen als auch die erhaltene Antwort in einem Event festhalten. Es muss außerdem bekannt sein, ob ein Event zum ersten Mal oder zum wiederholten Mal verarbeitet wird. Da Events unveränderlich sind, sollte diese Information nicht im Event direkt abgelegt werden. Stattdessen kann man die Events bei Anlage nummerieren und nach erfolgreicher Verarbeitung den Zählerstand aktualisieren.
Umgang mit Fehlern
Es muss eine Strategie entwickelt werden, wie damit umgegangen wird, wenn ein Event nicht erfolgreich verarbeitet werden kann. Ein derartiger Fehler kann temporären oder dauerhaften Charakter haben. Eine fehlerhaft implementierte Validierung kann z.B. dazu führen, dass ein Event KundeAngelegtV1 mit Name null im Event Log steht, aber nicht verarbeitet werden kann. Ist ein externes System, z.B. ein Mailserver, nicht erreichbar, kann es sich um ein temporäres Problem handeln. Die Lösung ist auch hier wieder invididuell. Im Fall der Mail kann das System nach einer definierten Zeitspanne von selbst einen erneuten Zustellungsversuch starten. Ein kaputtes Event in der Queue sollte nur in fachlich genau definierten Fällen komplett automatisiert behandelt werden.
DSGVO
Die Datenschutzgrundverordnung stellt eine besondere Herausforderung im Event Sourcing dar, denn Events sind per Definition nicht veränderlich. Damit können Events mit Personenbezug auch nicht nachträglich anonymisiert oder gelöscht werden. Es stellt sich also die Frage, ob Event Sourcing überhaupt für personenbezogene Daten eingesetzt werden sollte.
Fazit
Event Sourcing ist ein spannendes aber sehr herausforderndes Verfahren, das nur dann eingesetzt werden sollte, wenn die Vorteile dieses Paradigmas einen fachlichen Mehrwert bieten, der die mit dieser Technik verbundenen Nachteile kompensiert. Eine nicht zu unterschätzende Herausforderung sind der geringe Erfahrungsgrad, den die meisten Entwickler mit diesem Ansatz haben dürften. Die Gestaltung der Events und Verarbeitungslogik, der Interaktionen mit externen Systemen und der Fehlerbehandlungen erfordern sehr viel Sorgfalt und Voraussicht, damit das Projekt nicht im Chaos endet. Es ist ratsam den Einsatz von Event Sourcing auf ein Subsystem zu begrenzen, anstatt eine komplette Anwendung damit umzusetzen, da in der Regel nur bestimmte Komponenten davon besonders profitieren. Damit lässt sich auch der Schaden begrenzen, wenn sich die Entscheidung im Nachhinein doch als die falsche herausgestellt hat.