
Die Incident-Post-Mortem-Analyse (IPMA) ist die Betrachtung einer Störung im Nachhinein, wörtlich „nach dem Tod“. Die IPMA wird auch Incident Post-Mortem, Post-Mortem Review oder einfach nur Post-Mortem genannt. Ich werde für diesen Artikel die Abkürzung PMA verwenden, dabei aber immer die Betrachtung von Betriebsstörungen meinen. Die PMA spielt auch im Projektmanagement eine Rolle. Sie hat eine ähnliche Funktion wie die Retrospektive, hat aber einen formaleren Charakter, bietet auch Raum für intensive, ins Detail gehende technische Betrachtungen und kann je nach Ausgestaltung deutlich mehr Zeit in Anspruch nehmen.
Eine PMA ist auf den Punkt gebracht ein verschriftlichtes Dokument zu einer Störung, ihren Auswirkungen, den ergriffenen Maßnahmen zur Störungsbeseitigung, der grundlegenden Ursache (root cause) und den aus der Störung gesammelten Erkenntnissen und Folgemaßnahmen, um eine Wiederholung zu vermeiden und die Widerstandsfähigkeit zu erhöhen.
Warum eine PMA
Informationssysteme werden in Zeiten von Microservices, verteilten Systemen und Autoskalierung immer komplexer und ein nicht unerheblicher Teil davon fällt auf das Netzwerk. An dieser Stelle möchte ich kurz auf die fallacies of distributed computing verweisen, auf die ich in meinem Artikel zum ToxiProxy eingegangen bin.
Aber nicht nur das Netzwerk ist ein Garant dafür, dass Fehler unweigerlich passieren, auch Entwicklungen wie Continuous Deployment und DevOps tragen dazu bei. Häufige Deployments in Always-On-Services können langlaufende Tasks beeinflussen und finden oft in einem heterogenen Umfeld statt. Zu festen Maschinen gesellen sich Serverless-Systeme, neben horiziontal skalierbaren Applikationsservices werden auch Functions as a Service eingesetzt. Die Auswirkung eines Deployments verschiedenster Komponenten mehrere Male pro Tag ist viel schwieriger zu antizipieren, als ein über Wochen geplantes Update eines Monolithen mit vorgesehener Downtime alle paar Monate.
Ansätze wie DevOps ermöglichen viel Freiheit bei der Wahl der Technologie, mehr Innovation und eine kürzere Time-to-Market, können dabei aber auch zu Lasten der Betriebsstabilität gehen. Statt eines festen Betriebsteams für mehrere Entwicklungsteams, das über Jahre Erfahrung mit einem Web-Application-Server und eines relationalen Datenbanksystems sammeln konnte, finden sich nun oftmals auch Entwickler in der Ops-Rolle wieder und betreiben verschiedene NoSQL-Datenbanken, eine Mischung aus Functions und Services und nehmen Serverless-Dienste wie Amazon S3 oder Amazon DynamoDB in Anspruch – und sie müssen sich für alle diese Services mit den Vor- und Nachteilen und Besonderheiten im Betrieb auseinandersetzen. Dabei sind sie oft auch noch für krossfunktionale Aspekte wie Observability verantwortlich.
Störungen, die einfach nur behoben werden, können sich schnell wiederholen, miteinander multiplizieren und im schlimmsten Fall zu einer rechten Kaskade führen und das gesamte System außer Gefecht setzen. Störungen kosten nicht nur Zeit und Kraft, sondern gerne auch bares Geld, unzufriedene Kunden und einen Reputationsverlust.
PMAs sind eine Chance zu Lernen, Schwachstellen aufzudecken, die Wiederholung gleicher Fehler zu vermeiden, die Zeit zur Behebung einer Störung zu minimieren und in Teams die Zusammenarbeit, das Vertrauen und die Resilienz zu stärken. Teams können durch dokumentierte PMAs aber auch voneinander lernen. Auch Stakeholder können von PMAs profitieren. Für sie bedeutet eine PMA Transparenz, sie erhöht das Verständnis, wie es zu einem Vorfall kommen konnte, und stärkt das Vertrauen in das Team.
Fehlerkultur
Um PMAs im Unternehmen einzuführen, bedarf es einer geeigneten Fehlerkultur. Es ist insbesondere essentiell, beim Umgang mit Fehlern auf Schuldzuweisungen zu verzichten. Dadurch wird Beteiligten die Angst genommen, Fehler zu machen. Sie sollten auch keine Bestrafung oder negative Konsequenzen fürchten müssen. Eine Null-Fehler-Politik führt dazu, dass Ursachen und Handlungen verschleiert oder verschwiegen werden. Informationen werden zurückgehalten und Fehler wiederholen sich, da niemand offen über sie spricht und daraus lernt.
Über Fehler zu sprechen hilft aber nicht nur denjenigen, die sie selbst erleben mussten, auch andere Teams profitieren davon. Wenn ein Team schmerzhaft feststellen muss, dass der Verzicht auf Circuit Breaker ein ganzes System in den Tod reißen kann, obwohl es nur in einer kleinen Teilkomponente zu einem Verbindungsabbruch kam, warum sollten dann nicht auch alle anderen Teams von dieser Erkenntnis profitieren, anstatt die Erfahrung selbst machen zu müssen?
Für eine erfolgreiche PMA-Kultur sollte man immer davon ausgehen, dass jede beteiligte Person mit den ihr zur Verfügung stehenden Informationen ihr Bestes gegeben hat. Man darf auch nicht vergessen, dass meist mehrere Versäumnisse verschiedener Stellen auf unterschiedlichen Ebenen zu einer Situation geführt haben. Um sich dies konkret vor Augen zu führen, kann sich jeder Beteiligte die Frage stellen: „Was hätte ich konkret tun können, um die Störung zu vermeiden?“
Fragestellungen bei der Einführung
Um PMAs nachhaltig im Unternehmen zu etablieren, sollte man sich im Voraus mit einigen Fragestellungen befassen. Der wichtigste Punkt aus meiner Sicht zuerst: Lieber zu klein anfangen anstatt zu groß. PMAs sollten nicht zu einem bürokratischen Moloch verkommen und benötigen am Anfang Akzeptanz – von denen, die sie lesen, um zu erkennen, dass sie einen Mehrwert darstellen, und von denen, die sie schreiben, um anzuerkennen, dass der dadurch entstehenden Nutzen den notwendigen Aufwand übersteigt.
Eine der ersten Fragen, die ich bei Einführung von PMAs stellen würde, ist: Wann wird eine PMA geschrieben und wann nicht? Es sollte eindeutige Kriterien geben, wann auf jeden Fall eine PMA zu verfassen ist und wann darauf verzichtet werden kann. Ggf. kann es auch uneindeutige Fälle geben, bei denen im Team dann die begründete Entscheidung fällt, dass auf eine PMA verzichtet wird oder nicht. Folgende Kriterien könnten etwa maßgebend dafür sein, dass eine PMA geschrieben wird:
- Endkunden waren von der Störung unmittelbar betroffen
- Durch die Störung ist nachweislich Umsatz entgangen
- Es ist zu einem Datenverlust gekommen
- Die Störungsbehebung hat unverhältnismäßig lange gedauert
- Die Stakeholder haben eine PMA explizit angefordert
Eine weitere wichtige Frage ist: Wie werden PMAs verwendet? Wer ist die Zielgruppe und was fangen diese mit der PMA an? Wer trägt die Verantwortung für eine PMA? Wer nimmt sie ab? Ein Review-Prozess sollte minimal darin bestehen, dass ein bis zwei andere Teammitglieder sich die PMA durchlesen und für gut befinden. Wenn sich die PMA niemand durchliest, wird auch niemand seine Schlüsse daraus ziehen können. Je nach Zielgruppe und Verwendung können auch verschiedene Stakeholder am Review-Prozess beteiligt sein. Ab einer gewissen Prozessgröße sollte ein Verantwortlicher (owner) für die PMA definiert werden, der diese zwar nicht zwingend alleine schreibt und nicht einmal den größten Teil des Inhaltes beitragen muss, sich aber für die zeitnahe Fertigstellung und Abnahme verantwortlich zeigt und als Ansprechpartner für alle Stakeholder fungiert. Zu klären ist auch, wer die PMA tatsächlich schreibt bzw. daran mitwirkt. Handelt es sich um eine Person oder um mehrere? Darf die Person die Mithilfe anderer involvierter Personen zur Unterstützung anfordern, etwa eines 1st-Level-Mitarbeiters, der Aussagen zu Kundenmeldungen und zur Störungskommunikation machen kann? Wird für das Review ein Meeting angesetzt? Sollen die Teilnehmer sich darauf explizit vorbereiten und ggf. bestimmte Informationen beisteuern? Oder reicht es aus, wenn sich die Reviewer die PMA eigenständig durchlesen und per E-Mail ihr Okay geben?
Eine einheitliche Vorlage für PMAs sehe ich als unabdingbar, je nach Verwendung sollte aber definiert werden, wo PMAs abgelegt werden. Ist eine PMA nur kurzfristig interessant, kann sie als E-Mail an alle Stakeholder rausgehen. Ich denke in der Regel sollte sie aber zumindest in einem internen Wiki archiviert werden, damit man auch nach längerer Zeit noch Zugriff auf sie hat.
Sind spätere Auswertungen vorgesehen, kann eine PMA auch in einem Ticketsystem festgehalten werden. So lässt sich ein PMA-Ticket direkt mit dem jeweiligen Incident-Ticket verlinken und wichtige Auswertungskriterien können in eigene Felder eingetragen werden, statt im Beschreibungstext unterzugehen. Interessant können hier etwa die Schwere der Störung und ihre Dauer sein, ggf. noch differenziert nach vollständiger Downtime und eingeschränkter Verfügbarkeit / verschlechterter Performance. Auch die Komponenten und involvierten Teams können wichtige Kriterien sein, um über einen Zeitraum zu analysieren, wo es überdurchschnittlich oft zu Störungen kommt und wie sich die Anzahl der Störungen über einen Zeitraum entwickelt.
Aufbau
Eine PMA sollte so zeitnah wie möglich geschrieben werden, aber nicht während der Störungsbehebung. Solange die Störung noch akut ist, sollte der Fokus zu 100% darauf liegen, diese zu beseitigen. Ich würde spätestens am Folgetag mit dem Verfassen der PMA beginnen, da dann das Wissen noch frisch im Kopf ist.
Eine hilfreiche PMA enthält aus meiner Sicht mindestens die folgenden Inhalte:
- eine Zusammenfassung
- eine Beschreibung der Störungsauswirkungen
- eine Beschreibung des Root Cause
- eine Beschreibung der Lösung
- einen Zeitstrahl beginnend mit der Störungserkennung bis hin zur Störungsbehebung
- was aus der Störung gelernt wurde
- welche Folgemaßnahmen ergriffen wurden
Zusammenfassung
Die Zusammenfassung liefert in Kurzform die wichtigsten Informationen zur Störung. Sie enthält mindestens in Stichworten Informationen zur Dauer der Störung, zur Auswirkung und zum Root Cause und dient dabei zum einen den Stakeholdern, denen das technische Verständnis fehlt, die detaillierteren Ausführungen nachvollziehen zu können, hilft dabei aber auch jedem Leser, die wichtigsten Fakten in wenigen Sekunden zu erfassen. Die Zusammenfassung ist auch die erste Anlaufstelle, um sich in kurzer Zeit einen Überblick über die geschriebenen PMAs in einem bestimmten Zeitraum zu verschaffen.
Beschreibung der Störungsauswirkungen
In diesem Abschnitt geht es darum darzustellen, welchen Effekt die Störung hatte. Wie viele Endanwender waren betroffen? Wie hat sich die Störung für sie ausgewirkt? Ist es zu Datenverlusten gekommen? Welche Prozesse oder Schnittstellen waren nur eingeschränkt oder gar nicht nutzbar? Kann der Schaden beziffert werden?
Lösung
Hier wird geschildert, welche Schritte unternommen wurden, um die Störung zu beheben. Dabei sollte auch deutlich werden, ob die Lösung das Problem dauerhaft korrigiert oder ob es sich um einen Workaround handelt und z.B. nachträglich eine aufwändige Programmanpassung fällig ist. Ebenso sollte aus dem Text deutlich werden, ob es eine eindeutige Lösung gibt, oder eine Kombination verschiedener Maßnahmen den Fehler behoben hat. Dabei sollte auch erläutert werden, ob bekannt ist, welche der ergriffenen Schritte tatsächlich zur Lösung beigetragen haben und an welcher Stelle ggf. Unsicherheit besteht.
Zeitstrahl
Ein Zeitstrahl bildet alle über die Dauer der Störung eingetretenen relevanten Ereignisse chronologisch ab. Aus dem Zeitstrahl ergibt sich, wann das Problem erkannt wurde, wann der erste Alarm aufgetreten ist und das erste Störungsticket erstellt worden ist, wer zu welchem Zeitpunkt welche relevanten Beobachtungen gemacht hat und wann welche Schritte zur Störungsbehebung stattgefunden haben.
Ich fange eine PMA immer mit dem Zeitstrahl an, da sich bei der Erstellung oft schon ein Bild des möglichen Root Cause formt. Außerdem führt der Zeitstrahl einem nochmal genau vor Augen, welche Auswirkungen die Störung hatte und was sie letzlich behoben hat. Hochautomatisierte digitalisierte Prozesse sind eine gute Grundlage zur Erstellung eines Zeitstrahls. Genaue Uhrzeiten zur Kommunikation in Chat, E-Mail und weiteren Kollaborationsanwendungen kann man den jeweiligen Systemen entnehmen. Werden Deployments und Änderungen (Stichwort infrastructure as code) über CI/CD-Pipelines abgewickelt, ist nachvollziehbar, wann genau diese angewandt wurden. Ist man in der Public Cloud unterwegs, so lässt sich über Dienste wie AWS CloudTrail im Detail nachvollziehen, zu welchem Zeitpunkt welche API-Aufrufe getätigt worden sind. Ebenso sollten die Logs der Anwendung selbst oder involvierter Infrastrukturdienste herangezogen werden. War die Software selbst nicht mehr in der Lage, API-Aufrufe entgegenzunehmen, so könnten die Logs eines vorgeschalteten Application Loadbalancers weitere wichtige Informationen zutage bringen.
Beschreibung des Root Cause
Die Ermittlung des Root Cause kann einen großen Teil der Arbeit ausmachen, die in eine PMA fließt. Ich habe bewusst den englischen Begriff gewählt, da eine deutsche Übersetzung wie Kernursache es in meinen Augen nicht so sehr trifft wie die englische Bezeichnung.
Um später sinnvolle Folgemaßnahmen bestimmen zu können, muss der Root Cause bekannt sein. Kann dieser nicht bestimmt werden, lassen sich auch nur bedingt effektive Maßnahmen zur Prävention ergreifen. Letzlich kann dann nur die Erkennung (Monitoring) und Mitigation optimiert werden, aber der Fehler kann jederzeit wieder auftreten und wird es dann auch.
Die 5-W-Methode
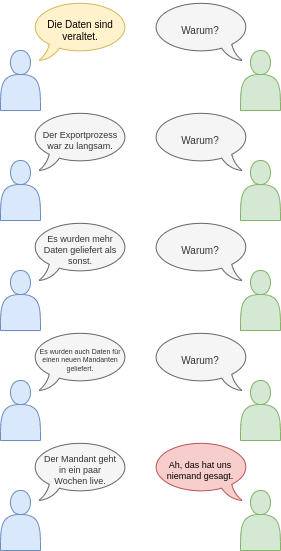
Bei der Ermittlung des Root Cause kann die 5-W-Methode, auch 5-Why-Methode, 5 Why oder einfach 5W genannt, unterstützen. Diese simple Vorgehensweise aus dem Bereich des Qualitätsmanagements hilft bei der Ursache-Wirkung-Bestimmung und drückt sich durch wiederholtes, gezieltes „Warum?“-Fragen aus. Die 5 ist dabei symbolisch gewählt. Die Warum-Frage sollte so oft gestellt werden, bis der Root Cause eindeutig identifiziert ist bzw. die benannte Ursache direkt adressiert werden kann, etwa durch organisatorische Maßnahmen.
Im Beispiel geht es um ein nicht näher bekanntes System, dessen Daten veraltet sind. Nach einigen Warum-Fragen stellt sich heraus, dass demnächst ein neuer Mandant freigeschaltet wird, durch den zusätzliche Daten anfallen. Die Daten wurden bereits an das System übermittelt, diese Tatsache war aber weder kommuniziert noch abgestimmt. Dementsprechend haben auch keine Tests stattgefunden, ob der Prozess die zeitlichen Anforderungen noch erfüllen kann, wenn die Daten für den neuen Mandanten zusätzlich verarbeitet werden.
Erkenntnisse und Folgemaßnahmen
Dieser Abschnitt bietet aus meiner Sicht einen der größten Mehrwerte einer PMA. Der Inhalt leitet sich oftmals aus dem Rest der PMA ab und ergibt sich zum Teil auch schon während der Störungsbehebung, zumindest wenn man noch nicht die angestrebte betriebliche Reife erreicht hat und feststellt, dass nicht alles rund läuft und so manches schneller gehen könnte.
Während es sich bei den Folgemaßnahmen um konkrete Aufgaben handelt, können sich Erkenntnisse in der organisatorischen Zusammenarbeit oder im Team erarbeiteten Guidelines und Best Practices widerspiegeln.
Aus den Auswirkungen der Störung kann sich z.B. ergeben, dass diese unnötig gravierend sind und durch ein Redesign leicht entschärft werden können, wenn ein ähnlich gelagertes Problem erneut auftritt. Vielleicht lässt sich die Nicht-Verfügbarkeit eines sehr fragilen Systems etwa durch einen Cache kompensieren?
Aus der beschriebenen Lösung kann sich ein Qualitätsdefizit abzeichnen, z.B. dass ein Team noch nicht bereit für Continuous Deployment ist und ein Bug früher hätte aufgedeckt werden müssen, idealerweise bereits durch automatisierte Tests, oder wenn es sich um einen schwer testbaren UI-Fehler handelt, spätestens im Sprint Review.
Durch die konkreten im Zeitstrahl beschriebenen Schritte kann ein KnowHow-Defizit aufgedeckt werden. Viele dieser Schritte waren vielleicht nicht effektiv und als Maßnahme muss ein Wissensaufbau zu einer bestimmten Technologie erfolgen.
Der Zeitstrahl kann auch reflektieren, dass die Störungsbehebung viel zu lange dauert, weil etwa die Deploy-Pipelines nicht in angemessener Zeit durchlaufen, oder der Lösungsweg war mit sehr vielen manuellen Schritten verbunden, bei denen leicht Fehler gemacht werden können, was die Störungsbehebung wiederum in die Länge zieht. Auch organisatorisches Optimierungspotenzial, etwa Missverständnisse bei den Verantwortlichkeiten mehrerer kollaborierender Teams, kann sich in der PMA abzeichnen.
Vielleicht ergibt sich aber auch, dass die Architekturvorgaben unzureichend erfüllt werden oder noch gar nicht explizit formuliert wurden. Gibt es SLA (Service Level Agreements)? Welche Qualitätsmerkmale hat das System? Ist es ausreichend redundant und performant? Wurden Qualitätsszenarien formuliert, die den Störungsfall abdecken und beschreiben, wie sich das System in bestimmten Ausnahmezuständen zu verhalten hat? Wurde das konkrete Störungsszenario vielleicht sogar betrachtet, aber als so unwahrscheinlich eingestuft, dass bewusst keine Maßnahmen zur Kompensation formuliert wurden?
Weitere Abschnitte
Welche Informationen sonst noch in die PMA gehören, hängt vom individuellen Umfeld ab. Handelt es sich um eine komplizierte Domäne bzw. geben Auswirkungen, Root Cause und Lösung zusammen kein ausreichend klares Bild ab, so lohnt sich eine gesonderte Einordnung des jeweiligen Kontextes bzw. die Schilderung weiterer Hintergrundinformationen. Um zu ermitteln, was sonst noch in die PMA gehören könnte, würde ich folgende Fragen (wieder) stellen: Wer ist die Zielgruppe? Was wird mit der PMA gemacht? Wird die PMA auch nach zwei Jahren gelesen und soll dabei für jeden verständlich sein? Wird der Inhalt diesen Anforderungen gerecht oder fehlen noch Informationen?
- Blameless PostMortems